AI绘画是通过扩散模型(Diffusion Models)和Transformer架构将文本转化为像素图像的技术。它已从早期的随机生成,演变为具备精准控制力的工业生产力工具。
到2026年3月,行业的争议焦点已从“AI是否是艺术”转向“如何将其转化为工业标准”。顶尖视觉艺术家不再纠结提示词(Prompt)是否算创作,而是将Midjourney v7或Stable Diffusion 3.5视为高级数字画笔。若仍将AI绘画看作抽卡游戏,将失去其最核心的价值:对视觉资产的绝对掌控力。
AI绘画正在重构图像生产链路。它并非替代绘画,而是驱动创作者从“执行者”升级为“导演”。这类似于摄影术出现后,画家不再苦练写实记录,转而探索印象派等更高维的艺术表达。
核心原理:从潜空间到像素的映射
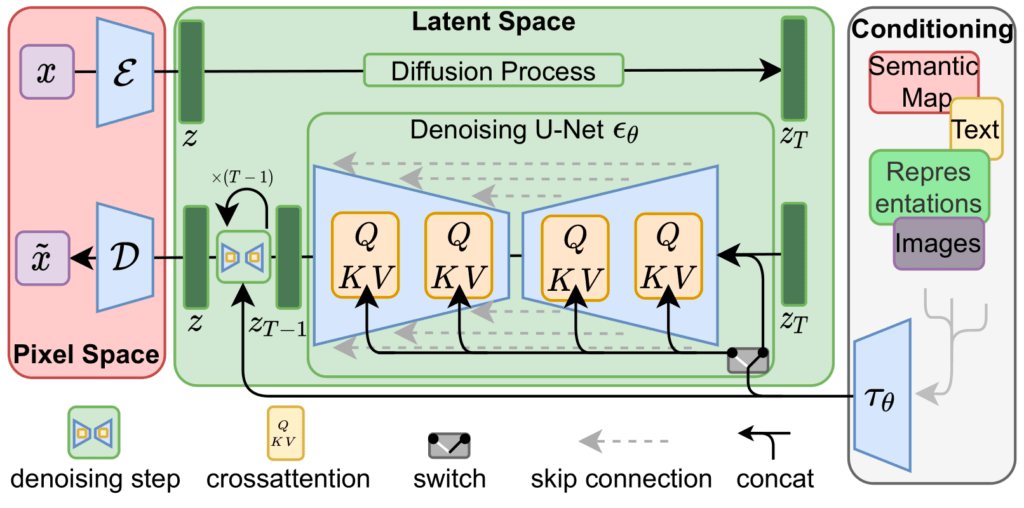
AI绘画的核心逻辑是“去噪”。在训练阶段,模型学习将图像逐渐添加高斯噪声直到混沌;生成阶段则相反,模型在文本引导下剔除噪声,还原图像。
这里的关键是“潜空间”(Latent Space)。模型存储的是数学分布而非具体图片。输入“赛博朋克街道”时,模型在潜空间定位到两个坐标的交集,再通过解码器转换成像素。这意味着AI并不理解“街道”的物理定义,而仅是基于概率分布进行像素组合。这解释了为何早期模型常画错手指——因为在统计概率中,手指数量并非严格常量。
工业级工作流实操指南
商业项目无法依赖随机生成的文字输入,必须构建“精准控制-细节增强-后期修正”的完整链路。以下以本地部署的Stable Diffusion为例。
第一步:利用ControlNet控制构图
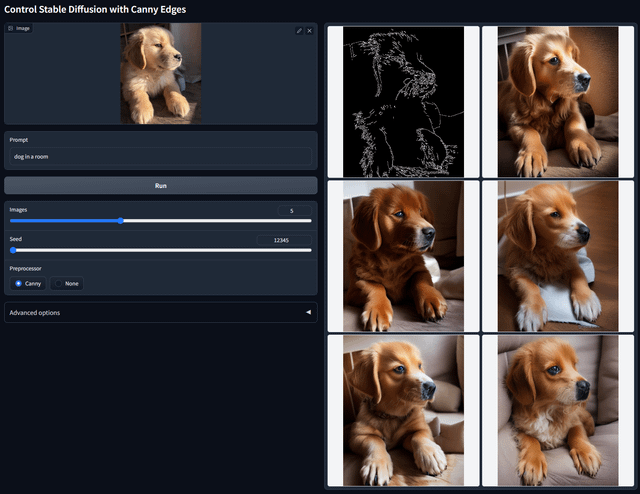
ControlNet是解决随机性的核心手段。它通过边缘线、深度图或人体骨架强制规定图像结构。
风险提醒:若参考图与提示词冲突(如骨架图是坐姿,提示词写“奔跑”),图像会发生扭曲。此时应简化提示词,让ControlNet决定结构,Prompt仅决定材质与光影。
第二步:使用LoRA模型确保一致性

通用大模型难以满足特定角色或画风的商业需求,LoRA(低秩自适应)是目前成本最低的微调方案。
第三步:通过Inpaint(局部重绘)精准修正
局部重绘是将AI画作转化为可交付作品的最后一步。
适用场景与局限性
AI绘画并非万能,其表现取决于应用维度。以下是针对不同需求的适用性分析:
| 应用维度 | 高效场景(优势) | 局限场景(劣势) |
|---|---|---|
| 生产效率 | 概念预演、氛围图、低客单价素材 | 高精度工业制图(缺乏物理尺寸概念) |
| 创作逻辑 | 发散性方案探索、色彩组合尝试 | 强逻辑连续叙事(角色绝对同一性) |
| 艺术价值 | 极致的光影与材质渲染 | 强调创作过程的纯粹情感表达 |
AI绘画 vs 传统数字绘画

成本逻辑发生迁移。AI单张成本极低,导致基础插画市场价格崩盘,单纯靠“画得像”的画师失去议价权。
效果呈现各有侧重。AI在光影、材质渲染上具有天然优势;而传统绘画在结构严谨性和细节刻意塑造上更胜一筹。
版权与风险共存。AI面临训练集侵权及著作权归属争议;传统绘画则有完整的创作链路,版权清晰。
任务类型完全不同。AI擅于发散性任务(如快速生成50个方案),传统绘画擅长收敛性任务(如精准修改具体纽扣形状)。
应对“动力危机”的建议
面对AI的效率,很多初学者会产生虚无感。但若将绘画定义为“观察世界并转化为视觉语言的能力”,AI反而是助推器。它能替代枯燥的重复填充,让创作者直接进入构图、色彩心理学和叙事的思考阶段。
建议构建“混合工作流”:用手绘确定结构和情感基调 $\rightarrow$ 用AI快速填充材质 $\rightarrow$ 回归手工精修。这既保留了人的主体意识,又利用了工业效率。
AI绘画是否会彻底替代画师?
不会替代,但会替代“只会执行而没有审美主导权”的画师。未来的竞争力在于如何将AI作为工具,通过导演思维驱动视觉产出。
对于初学者,应该优先学习Prompt还是基础绘画?
建议优先学习基础绘画(构图、色彩、人体结构)。因为Prompt是描述语言,如果你不具备基础视觉知识,你将无法精准地描述你想要的画面,从而陷入无休止的“抽卡”循环。
如何解决AI生成图像的版权风险?
在商业项目中,建议采用“AI生成草图 $\rightarrow$ 人工重绘 $\rightarrow$ 局部微调”的链路,增加人工创作占比,并尽量使用拥有商业授权的自有数据集训练LoRA模型。
行动建议
停止研究冗长的提示词词库。今天尝试一个实验:找一张你不满意的手绘作品,将其作为ControlNet参考图,尝试不同模型探索材质与光影的可能性。当你意识到AI是验证想法的工具而非思考的替代品时,才能真正掌控它。